TL;DR
In this post I show how .NET can be used to run state-of-the-art Natural Language Processing (NLP) models on "the edge". I provide a simple means for downloading and converting 'transformer' models from HuggingFace into models that can perform inference from managed .NET code on resource constrained devices. Finally I use Uno Platform to implement a cross-platform user-interface that allows real-time inference using these models.
Bitizen
At Bitizen we are working to revitalize democracy by promoting understanding of - and engagement with - politics in the UK. As a first step towards this goal, we have built a platform which is able to ingest hundreds of forms of data from across the political landscape and present this data to users as meaningful information. Much of this data is unstructured text so we use state-of-the-art machine learning models to help us analyse, categorise and summarise the data in a manner which facilitates downstream processing (i.e. cataloging, searching, presentation, etc).
Given that we are a .NET shop and that most research around ML and AI takes place using either R or Python, we usually deploy models by containerizing them in their native environment accompanied by an HTTP API. This allows us to call the model from .NET and works beautifully in our containerized, event-driven architecture.
However, as we move towards promoting engagement, we wanted our smartphone app to be... well... smart. For example, while users were interacting with the app (i.e. contributing to a discussion, searching for additional information, etc) we wanted to be able to perform inferences similar to those we run on the backend on the device itself. Privacy and latency considerations meant calling a hosted endpoint wasn't really a great solution so we started looking round for alternatives.
This is what we came up with...
A quick call-to-arms
Bitizen is currently looking for a web-developer and/or designer to help improve our online presence and bring some of our app smarts to the web. If you have an interest in UK politics and like the idea of working with a intrepid, young, bootstrapped start-up, please do drop us a line as we'd love to hear from you.
ML.NET vs NLP
Microsoft has a fairly strong ML offering for .NET developers in ML.NET. Indeed, I illustrated ML.NET's capabilities in a blog post last year titled 'State-of-the-art ML in UWP' which used a recent (at the time) ML model to perform salient object detection and image segmentation; a process very much suited to ML.NET strengths. Unfortunately the story around using ML.NET for NLP wasn't so strong and there were very few examples of how to use modern, 'transformer' based models from within ML.NET.
Until, that is, Gjeran Vlot published his BERT-ML.NET repository on GitHub. In an incredibly concise and simple implementation, he illustrated how a BERT based ONNX model could be used within ML.NET to perform 'Question Answering' (aka machine comprehension) based inference. This was fantastic and exactly what we had been looking for... except... we didn't want to perform (just) 'Question Answering' based inference. BERT - and related transformers - can be used for a broad variety of tasks including (but certainly not limited to) sentiment analysis, text classification and named entity recognition.
Given the other prepared models available in the ONNX Model Zoo - from which Gjeran sourced his model - seemed fairly limited, we decided to go model hunting...
Hugging Face
If you've not been to Hugging Face before, I would certainly recommend checking it out. Through the provision of excellent tooling and the formation of a vibrant, open community of users, Hugging Face have established themselves as the de-facto source for NLP models. On a single site you can explore, test and download models (with accompanying parameters and code) from a huge variety of sources (including Microsoft, Google and Elastic), pretrained (but with fine-tuning recommended) for a huge variety of use cases.
I decided that I wanted to initially try something that would give me quantifiable results (i.e. something more than just a probability) and knew that I wanted to try to run a model on an 'edge' (i.e. resource constrained) device. This meant finding an alternative to the BERT based models which are typically in excess of 400Mb.
Fortunately Hugging Face had me covered and, in short order, I had decided to use a DistilBERT based model trained for Token Classification (aka Named Entity Recognition). After quickly experimenting with a few, I found a model by Elastic that provided pretty good results and, at less than half the size of a comparable BERT model, seemed like it might be usable on an edge device.
Open Neural Network Exchange
However, Hugging Face provides models for ease of consumption from it's own toolkit which usually means they're made available in either PyTorch or Tensorflow based formats. ML.NET, on the other hand, is only able to load models in the Open Neural Network Exchange (ONNX) format. This meant I needed to convert the models before I could use them.
Yet again, Hugging Face came to the rescue through the provision of an API which allows export of their models to ONNX. Knowing I would likely want to use multiple models in this manner (and not wanting to install various versions of Python on my workstation) I decided to build a docker container which would run the conversion and save the converted ONNX model to a mapped location. This proved to be shockingly easy with the image built using just a single Dockerfile containing:
FROM python:latest
RUN pip install tensorflow
RUN pip install torch
RUN pip install transformers
RUN pip install keras2onnx
RUN pip install onnxruntime
ENTRYPOINT [ "python", "/usr/local/lib/python3.9/site-packages/transformers/convert_graph_to_onnx.py" ]
This could then be run from Powershell like this:
docker run --rm -v ${PWD}/Output:/Output ibebbs/huggingfacetoonnx:latest --framework pt --opset 12 --pipeline ner --model elastic/distilbert-base-cased-finetuned-conll03-english /Output/elastic/distilbert-base-cased-finetuned-conll03-english.onnx
Whereupon the script will download the specified model (in this case 'elastic/distilbert-base-cased-finetuned-conll03-english') using the specified framework ('pt' for PyTorch, 'tf' for Tensorflow), convert it to ONNX (using opset 12) including layers for the specific pipeline (in this case 'ner' for named entity recognition) and finally write the converted model to the 'Output/elastic' subdirectory of the current folder.
Should you wish to use this docker image, it is available - accompanied by full usage instructions - on Docker Hub including a link to the source repository.
Netron
After downloading and converting the model, we need to examine it to determine the shape of the input and output layers. This is very easily done with Netron.
Shown below is (a small section of) the DistilBERT model. By clicking on the 'input_ids' node a side-pane is shown which includes all the information we need.
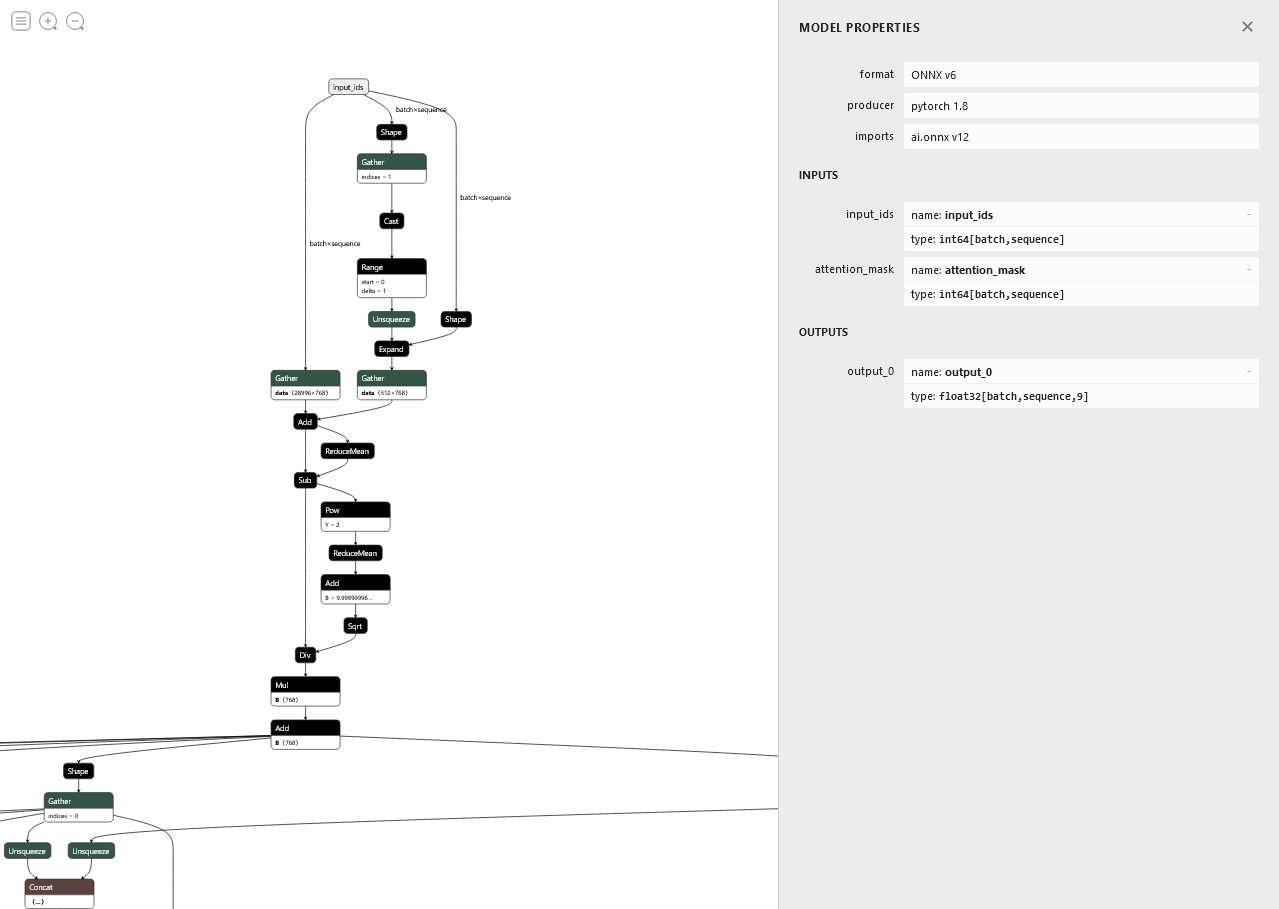
As can be seen, Netron shows us the two inputs to the model: input_ids and attention_mask, both of which being two dimensional arrays of Int64 values. It also shows us the output from the model: output_0, a three dimensional array of float.
Model Input
While using this model for inference, the attention_mask input is simply filled with 1s (each token has equal attention) so we will not discuss this input any further. Equally we will not be using multiple batches in this project so the batch dimension can be ignored leaving us with a single, sequence dimension of values to fill for input_ids.
In this model, the size of the sequence dimension is not specified illustrating that this model can accept dynamically sized input. As such, should we wanted to perform NLP on the sentence "Sarah lives in London and works for Acme Corporation", we might expect to provide something like this to the input_ids input:
| Sequence | Word |
|---|---|
| 0 | Sarah |
| 1 | lives |
| 2 | in |
| 3 | London |
| 4 | and |
| 5 | works |
| 6 | for |
| 7 | Acme |
| 8 | Corporation. |
But, as can be seen above, the model accepts integers, not strings, so we must first 'tokenize' the input using a vocabulary specific to this model. This is done by downloading the vocabulary for the model from Hugging Face (available here) then using a specific tokenizer to convert the input text into a series of tokens in a format the model expects; for BERT based models, a "WordPiece Tokenizer" is used.
Fortunately for us, we're able to use the "WordPieceTokenizer" provided in Gjeran's BERT-ML.NET repository. Running the above input through this tokenizer would give use the following input_ids value:
| Sequence | Token Id | Token |
|---|---|---|
| 0 | 101 | [CLS] |
| 1 | 21718 | sa |
| 2 | 10659 | ##rah |
| 3 | 2491 | lives |
| 4 | 1107 | in |
| 5 | 25338 | lo |
| 6 | 17996 | ##ndon |
| 7 | 1105 | and |
| 8 | 1759 | works |
| 9 | 1111 | for |
| 10 | 170 | a |
| 11 | 1665 | ##c |
| 12 | 3263 | ##me |
| 13 | 9715 | corporation |
| 14 | 119 | . |
| 15 | 102 | [SEP] |
And it's these 'Token Ids' that are the input to our model.
Model Output
As we can see, the output_0 layer consists of the same batch and sequence dimensions but adds an additional dimension with 9 elements. This additional dimension contains the probability of the token at [batch,sequence] belonging to a specific classification. The labels for each classifications are provided by the model's 'config.json' file on Hugging Face as shown below:
{
...
"id2label": {
"0": "O",
"1": "B-PER",
"2": "I-PER",
"3": "B-ORG",
"4": "I-ORG",
"5": "B-LOC",
"6": "I-LOC",
"7": "B-MISC",
"8": "I-MISC"
},
...
}
As can be seen, this model uses Inside-outside-beginning tagging to delineate the beginning and inside of a specific classification from other classifications but, for the most part we can just treat this as 5 classifications:
- Other
- Person
- Organisation
- Location
- Misc
BertONNX
Armed with the model and an understanding of how to provide input/interpret output, I spiked out a quick .NET Core test project. Looking to simplify Gjeran's implementation even further I ended up with end-to-end, command line based inference engine in just 7 classes (including Gjeran's WordPieceTokenizer along with a Hugging Face configuration deserializer).
Should you wish to take a look, the source for this spike can be found in my BertOnnx repository on Github.
By far the biggest headache was working out how to shape the input (Feature) and output (Result) types to match the expected model shapes. ML.NET uses [ColumnName([name])] and [VectorType([x,y])] property attributes to bind properties to the model but, given the model was capable of processing dynamically sized input, I wasn't sure what values to use for the VectorType attribute.
Initially I tried omitting shape information from the attribute ([VectorType]) whereupon the app unceremoniously crashed with the error "Variable length input columns not supported". A little searching revealed that this error meant exactly what it said and we couldn't use dynamically sized input with ML.NET!
So, instead I elected to use try a different approach and pad all input to a specific size (256 elements). This gave me Feature and Result types that looked like this:
public class Feature
{
[VectorType(1, 256)]
[ColumnName("input_ids")]
public long[] Tokens { get; set; }
[VectorType(1, 256)]
[ColumnName("attention_mask")]
public long[] Attention { get; set; }
}
public class Result
{
[VectorType(1,256,9)]
[ColumnName("output_0")]
public float[] Output { get; set; }
}
After this it was fairly plain sailing and in short order I had this:
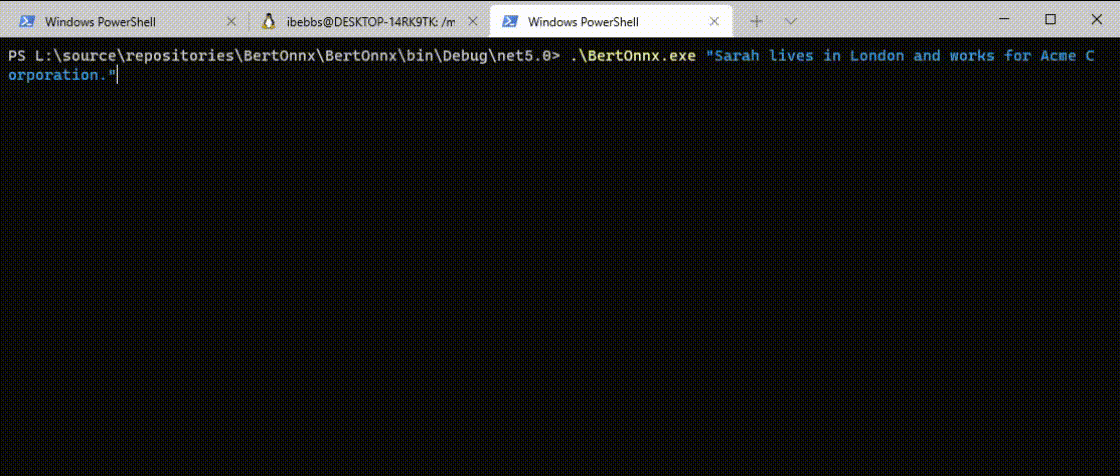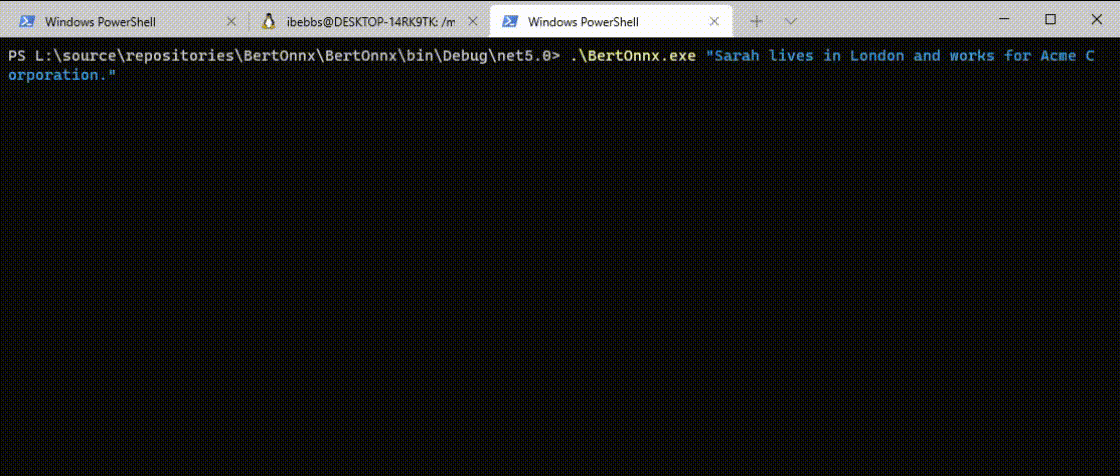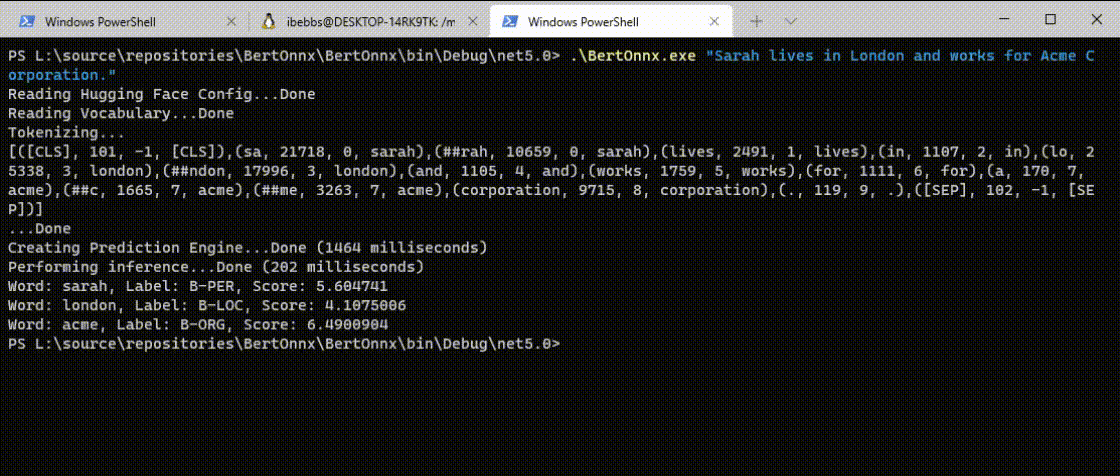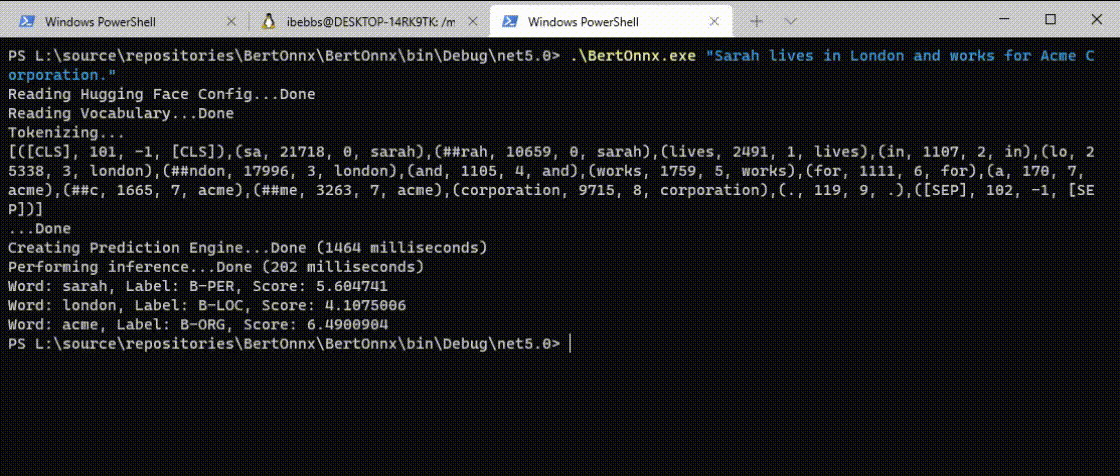
As you can see, the DistilBERT model correct identifies 'Sarah' as a 'B-PER' (person), 'London' as a 'B-LOC' (location) and 'Acme' as a 'B-ORG' (organisation) in just 202ms. Perfect!
Quantization
While having a custom built inference engine was pretty cool, I was a little concerned about memory consumption if I wanted to use the model on edge devices. Despite the DistilBERT model being significantly smaller than full BERT, memory consumption during inference hit around 1Gb. This would almost certainly be a stretch for many of the devices I'd like to run this model on.
Fortunately, ONNX has a little trick up it's sleeve called 'Quantization'.
Quoting this article on the matter:
Quantization approximates floating-point numbers with lower bit width numbers, dramatically reducing memory footprint and accelerating performance. Quantization can introduce accuracy loss since fewer bits limit the precision and range of values. However, researchers have extensively demonstrated that weights and activations can be represented using 8-bit integers (INT8) without incurring significant loss in accuracy.
Compared to FP32, INT8 representation reduces data storage and bandwidth by 4x, which also reduces energy consumed. In terms of inference performance, integer computation is more efficient than floating-point math.
Incredibly, quantizing a model using Hugging Face's ONNX export is as simple as specifying a --quantize flag. This meant generating a quantized version of the model took no more than effort than just running the following command:
docker run --rm -v ${PWD}/Output:/Output ibebbs/huggingfacetoonnx:latest --framework pt --opset 12 --pipeline ner --model elastic/distilbert-base-cased-finetuned-conll03-english --quantize /Output/quantized-distilbert-base-cased-finetuned-conll03-english/model.onnx
The quantized version of the model was just 64Mb (75% smaller) and, due to it's input and output layers remaining unchanged, it was a drop in replacement for the unquantized model. Running with the quantized version resulted in:
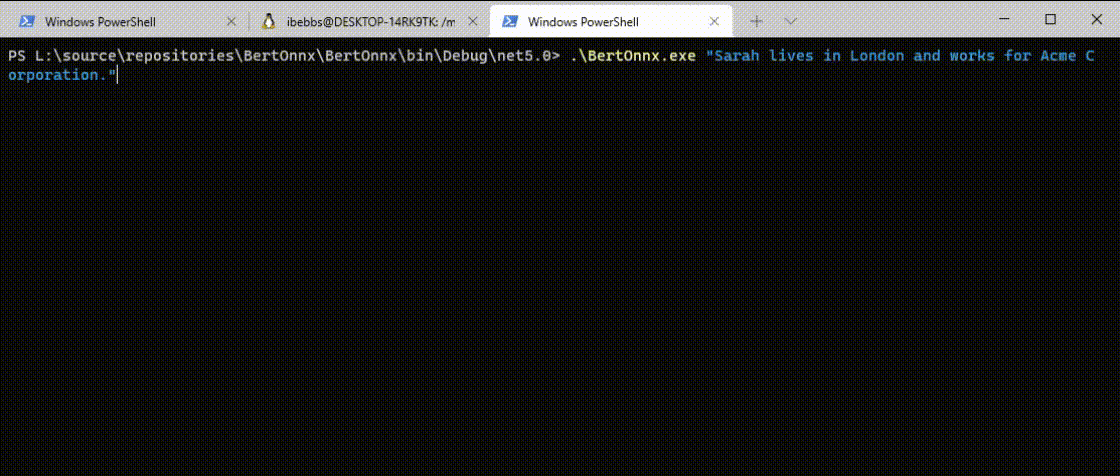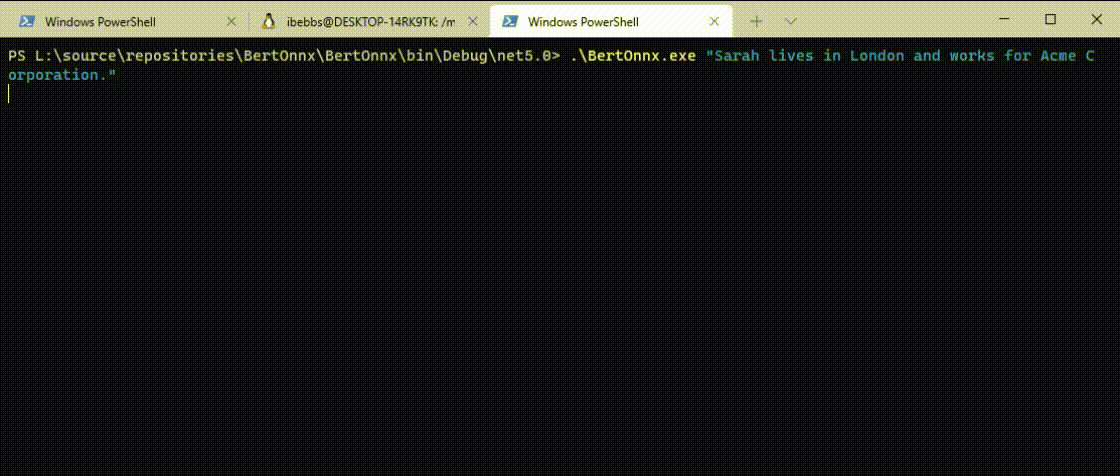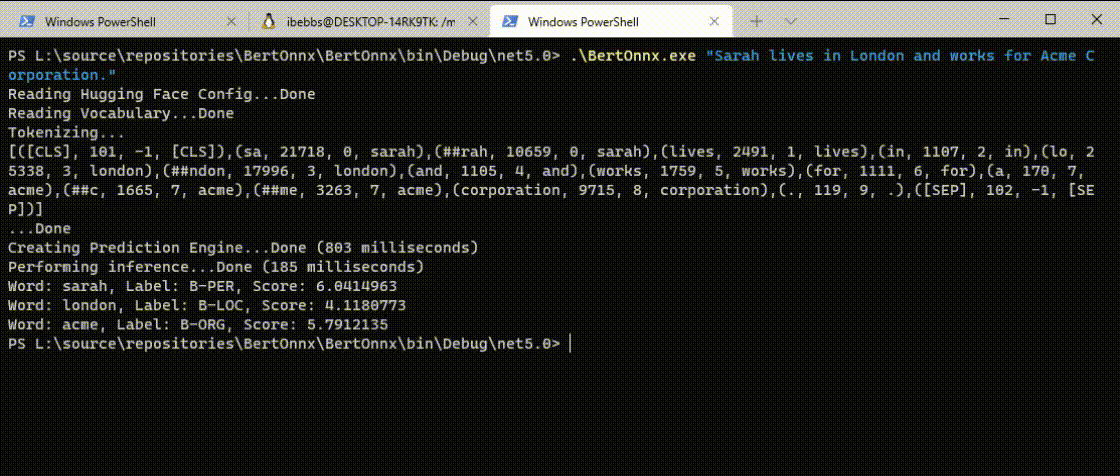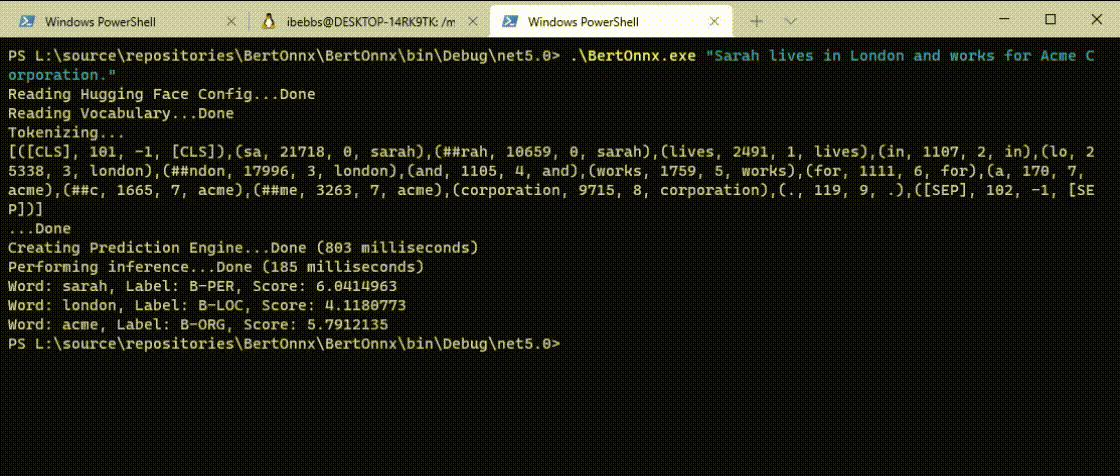
As you can see, the model loaded significantly faster and inference speed also got a boost. Best of all, memory consumption during inference was reduced to just 265Mb, definitely within the realms of possibility for an edge device.
Buoyed by this success, I pushed on to...
UnoOnnx
As per the initial driver for this exploration, I wanted an app on an edge device that would allow me to perform interactive inference. Knowing that Uno Platform could easily create apps that run across a variety of devices, I decided to whip up an app to do just this.
And so was born UnoOnnx ('Oo-noo-nx'?):
As you can see, the first inference is quite slow as it (lazily) loads the model but subsequent inferences are more than fast enough for an interactive app.
Then, with a little Uno Platform magic, I ran exactly the same code under Linux ('Oo-noo-nux'?):
(BTW, Loading the model isn't usually that slow - my machine was busy doing something else while I recorded this video).
Pretty Neat!
As with BertOnnx, the source for UnoOnnx is available on GitHub if you want to take a look.
Moving Forward
In a subsequent post - and assuming there's sufficient interest - I hope to illustrate how to run these models on mobile devices (i.e. Android & iOS). If this is of interest to you, please drop me a tweet and/or star the repositories above to let me know.
Conclusion
As you can see, with the right toolset and a little bit of knowledge, it is fairly straight forward to use state-of-the-art machine learning models from .NET even within the resource constrained environment of an 'edge' device. While some use-cases that depend on sequence length (i.e. sentiment analysis) might be tricky to implement effectively in ML.NET, many other uses (text generation/classification, machine comprehension, translation, etc) should be pretty much pattern part.
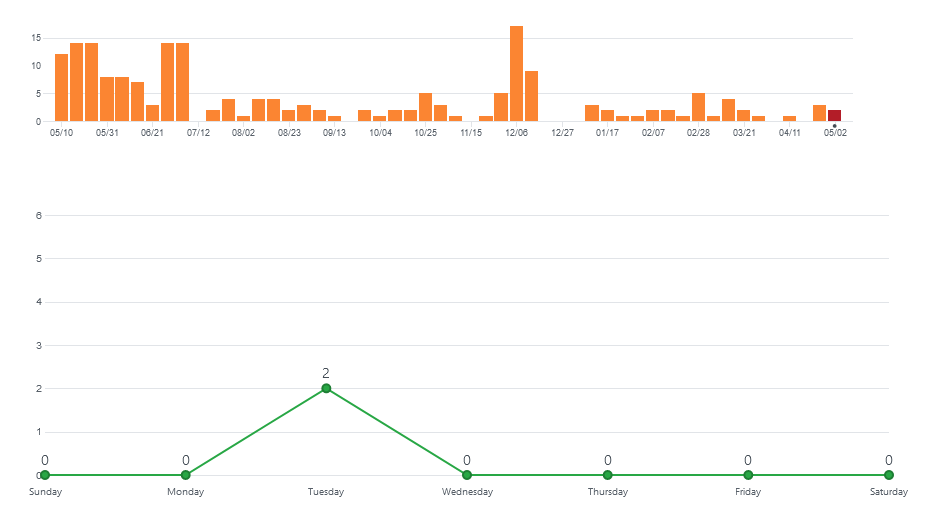
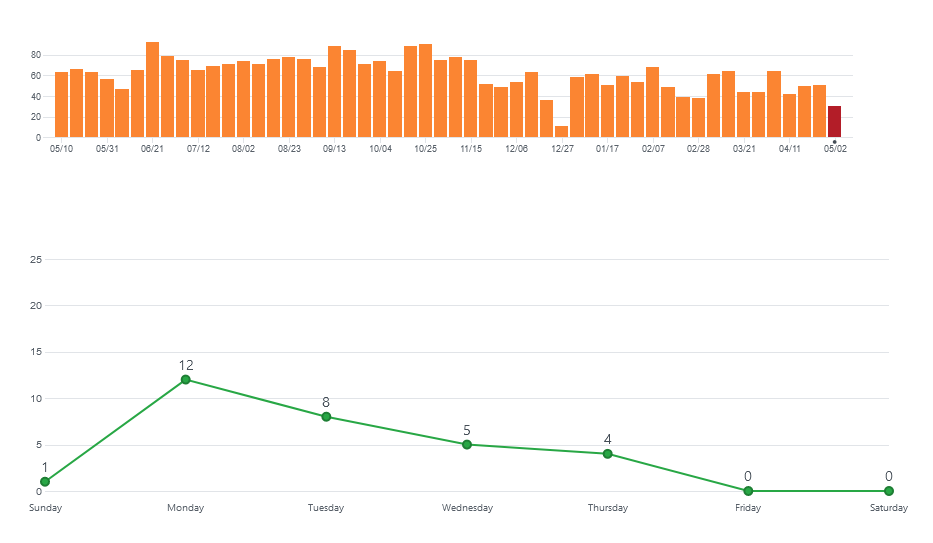
However, working through the above has left me extremely concerned about Microsoft's strategy towards desktop (i.e. non-web) development. It seems to me that many of Microsoft's frameworks and SDKs for .NET desktop development are suffering from a distinct lack of resourcing/focus meaning development is slow and the frameworks are getting left behind by other languages/platforms. For example, here is the commit chart of ML.NET comparer to Hugging Face's native API:
|
|
I think you'll agree, one of these projects looks significantly healthier than the other.
Furthermore, Microsoft's strategy/execution around UWP/WinUI/Project Reunion is an utter shambles. While I understand WinUI 3.0 is very new and Project Reunion still in preview, I honestly couldn't believe how poor the development experience was with these technologies.
@Microsoft, were it not for Uno Platform providing at least a modicum of continuity through the disastrous landscape that is Windows UI development, I - and I believe many others - would have jumped ship to other UI platforms a long time ago. Please step up your game here. Many of us who have stuck with Windows UI technologies despite its fragmented and frustrating history really are getting to the end of our tether.
Finally
If you're interested in deploying state-of-the-art machine learning models within .NET or using the Uno Platform to deliver cross-platform apps, then please feel free to drop me a line using any of the links below or from my about page. As a freelance software developer and .NET consultant I'm always interested in hearing from potential new clients or ideas for new collaborations.